書籍
まとめ
トレンドを可視化する方法は二つある
何かしらでSmoothingする方法
- 移動平均
- pros: シンプル
- cons: あんまり滑らかでない
- LOESS
- pros: 滑らかで、もっともそれっぽい結果を返す(特に理由なければこれを使うべき)
- cons: 計算が重い
- Spline
- pros: 滑らかで計算も重くない
- cons: 手法が多くあるが恣意的に選んで結果を操作できてしまう
ターゲットとなる関数を決めて当てはめる(回帰)
- 回帰したい関数がわかるときはこちらを選ぶ
前置き
散布図(ch12)や時系列データ(ch3)を可視化するとき、個々のデータの詳細よりも全体的なデータのトレンドのほうの興味があることが多い。そういう場合はトレンドを個々のデータポイントの代わりにもしくは上書きすることで、データの重要な特徴を素早く伝えることができる。
トレンドを決定する基本的な方法には二種類あり、
- 移動平均などでスムージングする方法
- 何かしらの関数をデータポイントにフィットする方法
トレンドを決定することができたら、そこからトレンドからのずれを計算したり、周期的な成分や一過的な成分などに分類することも有用かもしれない
1. Smoothing
以下のダウ平均のグラフをみると
- 2008年の暴落後から2009年3月まで暴落は続いている
- 2009年の残りでは緩やかに回復している
という傾向があるが、このような長期的な傾向を可視化しつつ短期的な変動を強調しないようにするにはどうすればよいか?
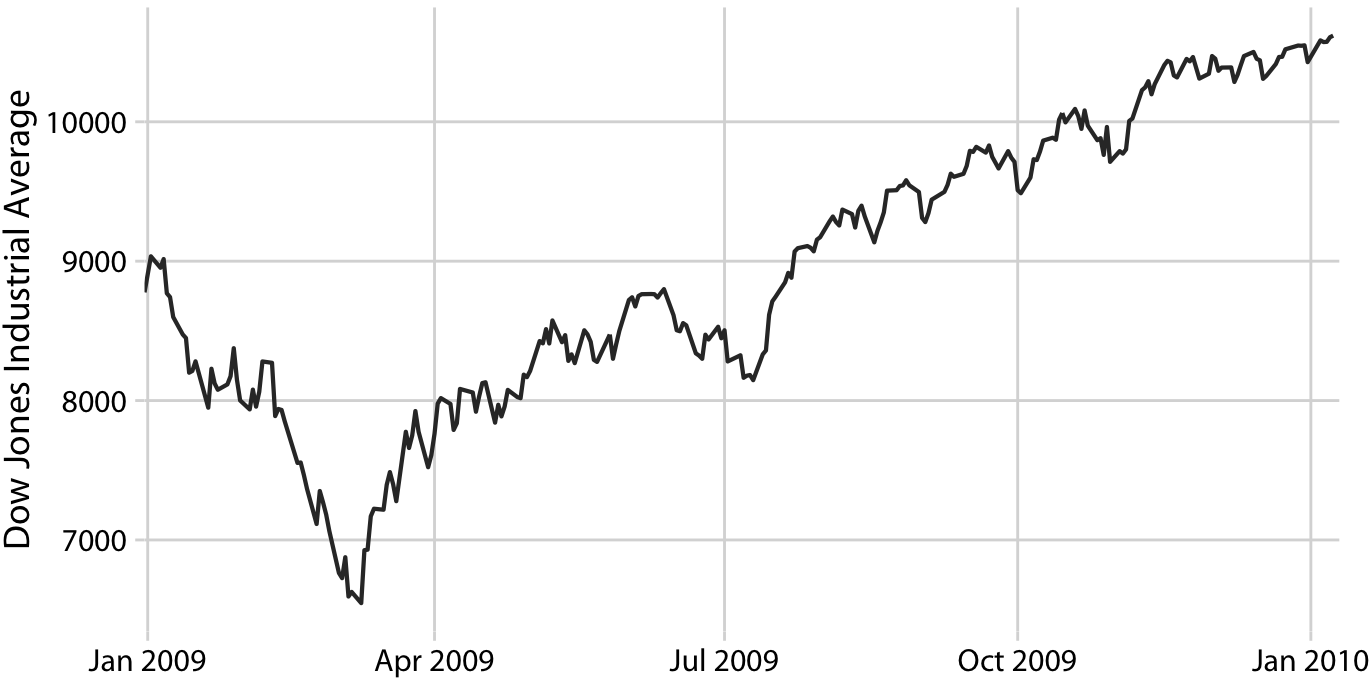
Smoothingは無関係な詳細やノイズを除去する一方でデータのキーパターンを捉える効果がある。金融アナリスト普通、移動平均を使うことで株式データをSmoothingしている。
N日移動平均(金融アナリストの場合)
ウィンドウサイズをN日とする。このときのN日の移動平均は
としてあらわされる。統計学者の場合は中央値になるようにプロットする。つまりN日の移動平均を
として定義する(上の式はNが偶数の場合は修正が必要です)
金融アナリストの流の定義では、ウインドウサイズが大きくなるほどaのグラフのように元のデータよりおくれる。(x軸が一致しない)一方統計学者のように定義すればbのように元データに一致する。
(いろいろ書いていますがどちらでも値自体は同じでグラフのX軸のどこにプロットするかというだけの違いです)
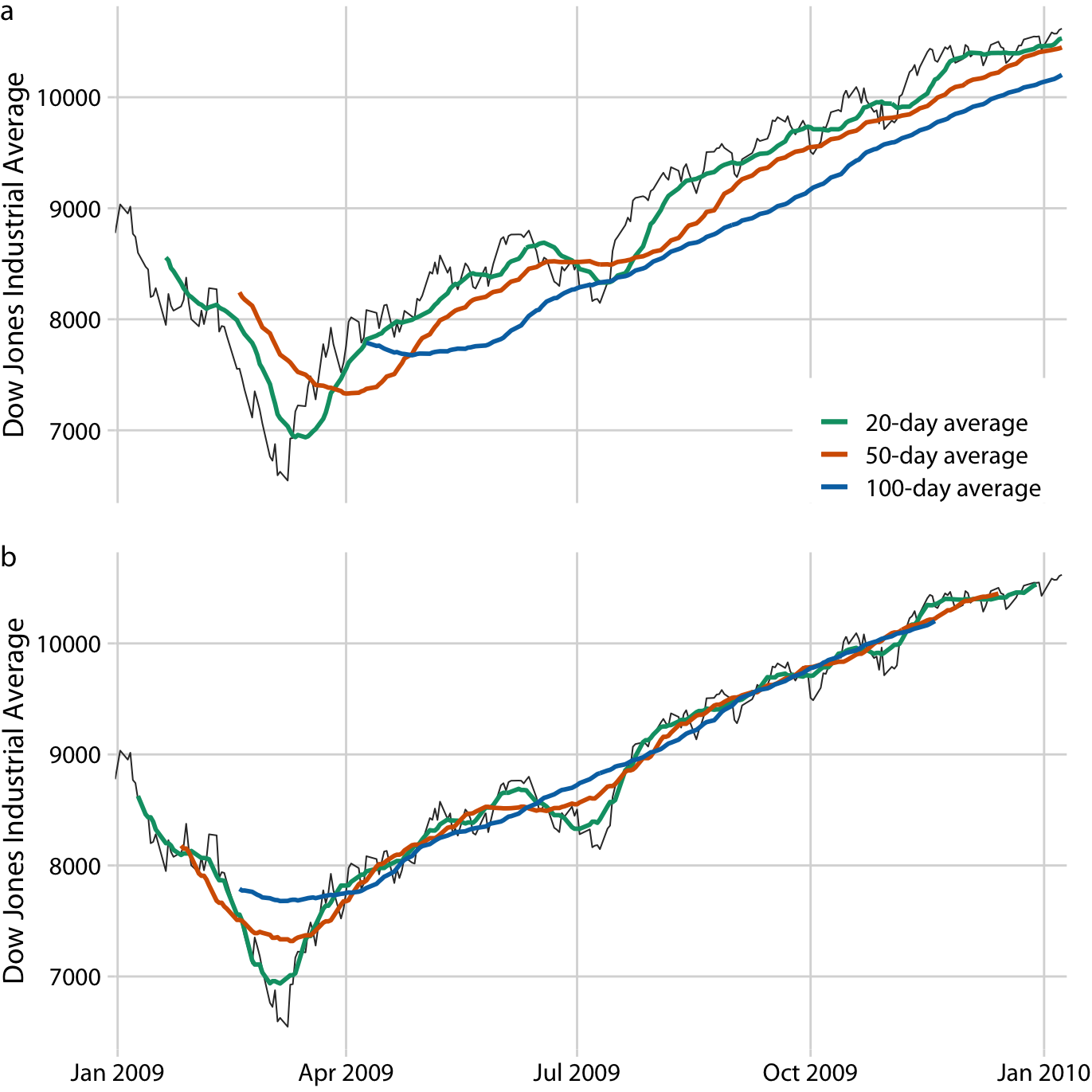
グラフからウィンドウサイズの大きさが、Smoothingしたあとに残り続ける変動の大小を決めていることがわかる。
(つまり、ウィンドウサイズが大きい → Smoothingの効果が大きい)
実際20日移動平均では短期のスパイクは除去されつつも日々のデータの変動に追従している。一方100日移動平均では本質的な数週間にわたる暴落やスパイクすらも除去されてしまう。
移動平均は最も単純なアプローチなので明確な弱点もあり、
Smoothingされた曲線は元のデータより短くなる。また計算式より始点か終端の移動平均は定義できない。またSmoothingの効果を強くしようとすればウィンドウサイズを大きくする必要があり、その分曲線がさらに短くなる。
大きなウィンドウサイズを利用したとしても、移動平均は必ずしもSmoothにならない。ウインドウの端点のデータの入れ替わりによって、移動平均に対して目に見えてしまうような影響を与えてしまう。(注: この場合の滑らかというのは数学的な微分可能ということを意味していると思います。)
統計学者は移動平均の欠点を緩和する多数の手法を開発してきた。これらの手法の計算コストは重いが現代のコンピューターではすぐに実行可能である。
LOESS
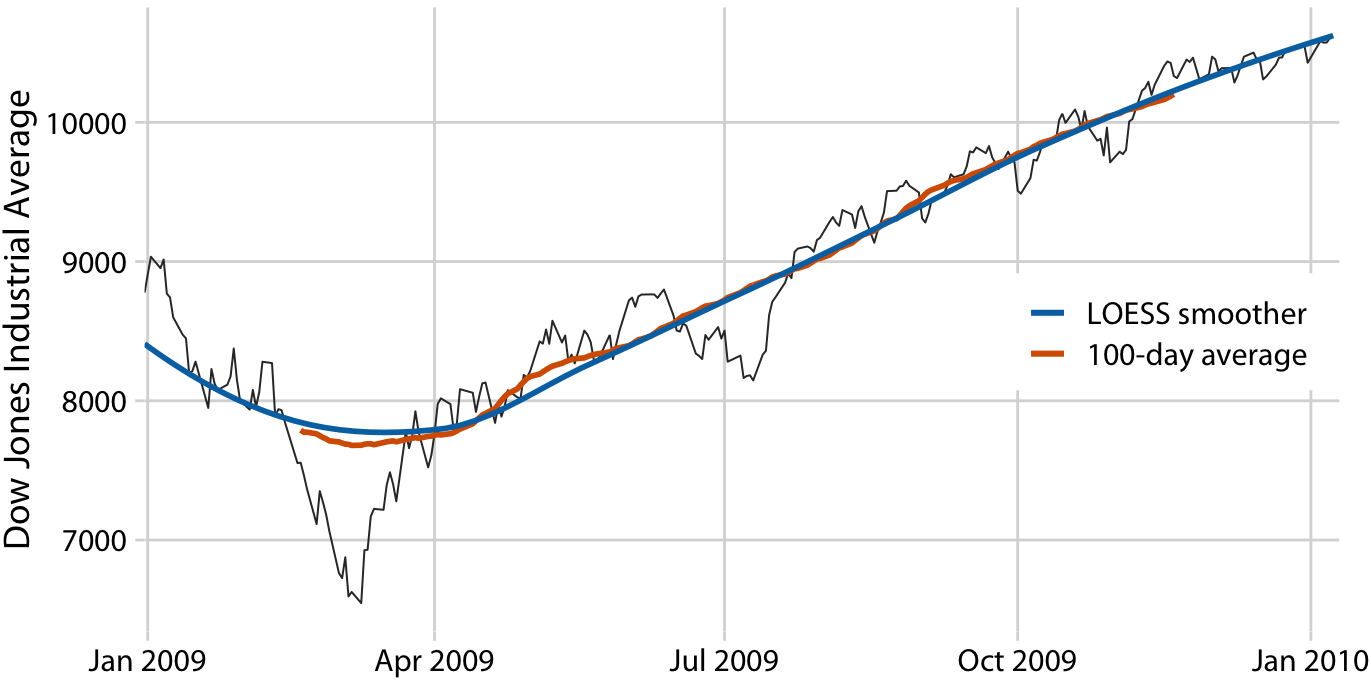
移動平均の代わりとして広く使われている手法の一つがLOESS(locally estimated scatterplot smoothing)である。この手法では低次多項式を用いて局所的にデータポイントを回帰する。重要なのは部分集合の中心付近のデータポイントほど大きい重みがつけられることである。(注: 移動平均ではウインドウサイズにある各データポイントの重みは同じであった)このスキームにより移動平均よりはるかに滑らかな曲線が得られる。(注: 微分可能という意味で滑らかを使っていると思います。)また下のグラフではLOESSは100日移動平均と似ているように見えるが、これは本質的でなくパラメータによっては20日、50日移動平均に似せることができる。
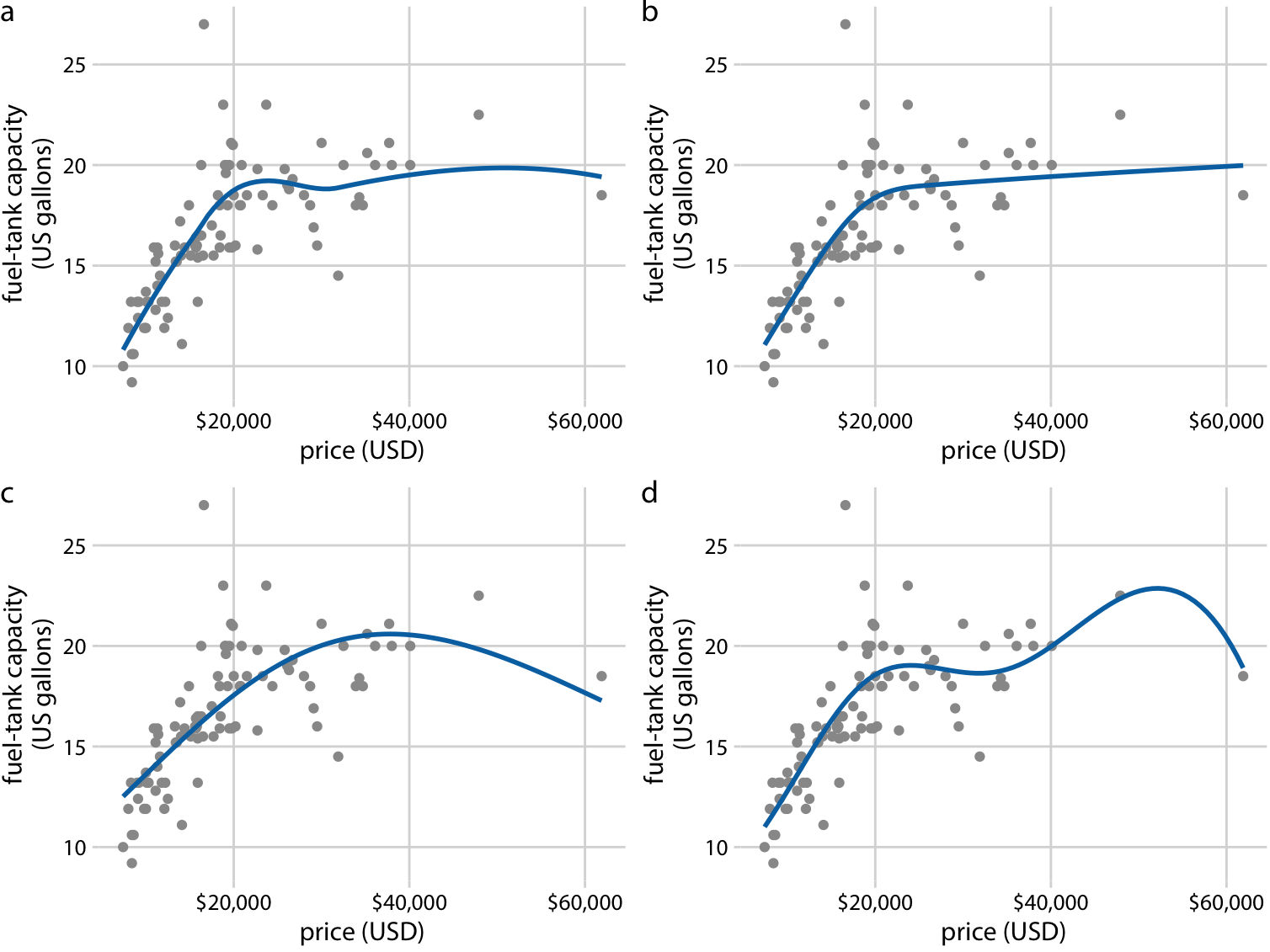
もう一つ重要なのはLOESSは時系列データに制限された手法ではないということである。名前から明らかなようにLOESSは散布図(scatterplot)に適用可能である。例えば下のように車の燃料タンクの容量と値段の散布図に対しても適用できる。(注: もちろんこの散布図には移動平均は適用できない)
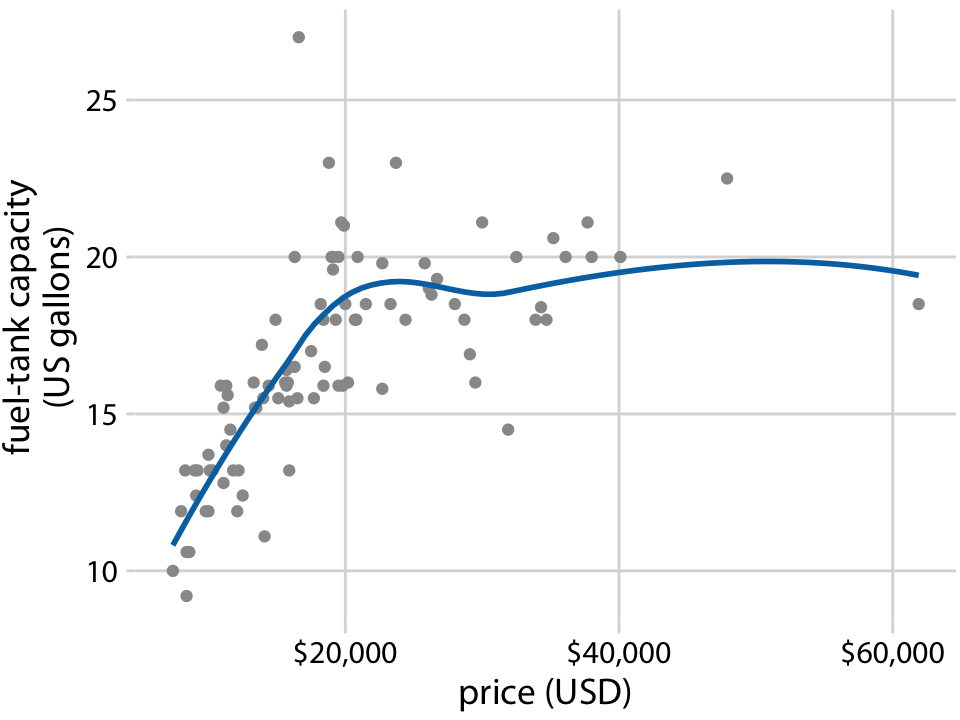
LOESSは人間の目に妥当にみえるので人気がある。ただLOESSは多数の独立した回帰が必要で、これは現代の計算機を持っても大きいデータセットの場合は計算に時間がかかる。
LOESSは普通の統計本には載っていない気がします。私のてもとにあるのでのっていたのは以下のものだけです。

スプライン
Splineとは区分的に多項式であり、常に滑らかに見えるもののことである。スプラインを扱う上でknotと用語が出てくる。
knotsはここのスプラインのセグメントの端点である。例えばk個のセグメントからなるスプラインを作るにはk+1個のknotが必要になる。
スプラインは計算効率面でメリットがあるが、knotの数がそれほど多くないときには欠点もある。
参考URL:
最も重要なのはスプラインには3次スプライン、B−スプライン, 薄板スプライン、ガウス過程スプラインなどの多くの種類があるが、どれを選ぶべきかというのは明確でない。
スプラインの種類の選択やknotsの数の選択によって、図のように同じデータであっても大きく異なったSmoothingしたグラフになってしまう。
多くのデータ可視化のためのソフトウェアはSmoothing機能を備えているであろうし、それは恐らくLOESSやスプラインとして実装されているであろう。Smoothingのための手法はGAM(generalized additive model)という。GAMはLOESSやスプラインといった個々のSmoothingのための手法のスーパセットである。
重要なのはSmoothingの機能というのはGAMのモデルに強く依存しているということを認識することである。(モデルが変われば結果も変わる。)
Smoothingした結果には注意深くあるべきである。同じデータセットであっても様々な方法でSmoothingされる。(のでSmoothingした後の結果は異なる)
定義した関数形式でトレンドを可視化する
LOESSやSplineでの前出のグラフのように汎用的なSmoothingの手法(GAMのモデル)はときには予測と異なる振る舞いをする。またそれらのSmoothingによるパラメータ推定は意味のある結果をもたらさない。そんなわけで可能であれば意味のあるパラメータをもつ特定の曲線を使うほうが望ましい。(回帰: regressionといわないのは著者のポリシー?やっていることは回帰だけど...)
例えば燃料タンクのデータの場合は、はじめは線形に上昇して定数値の漸近するような曲線が必要になる。
といった関数は要件を満たしておりここでA, Bは定数である。
これはxが十分小さい時は線形とみなせ、xが十分に大きいときはAに漸近し、さらにxにおきて狭義単調増加である。(数Ⅲ的にxが小さい場合は [tex: ex = x]とみなせます。)
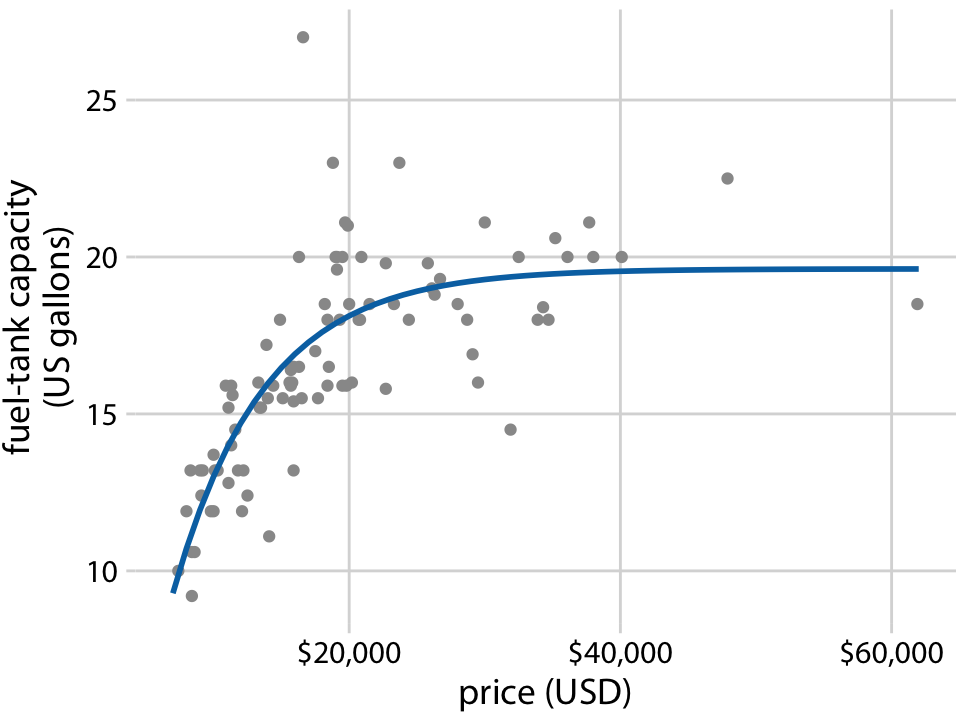
14-6の図をみると、この関数のあてはまりはこれまでのSmoothing(LOESS, Spline)のものと少なくとも同等以上であることがわかる。
線形の場合
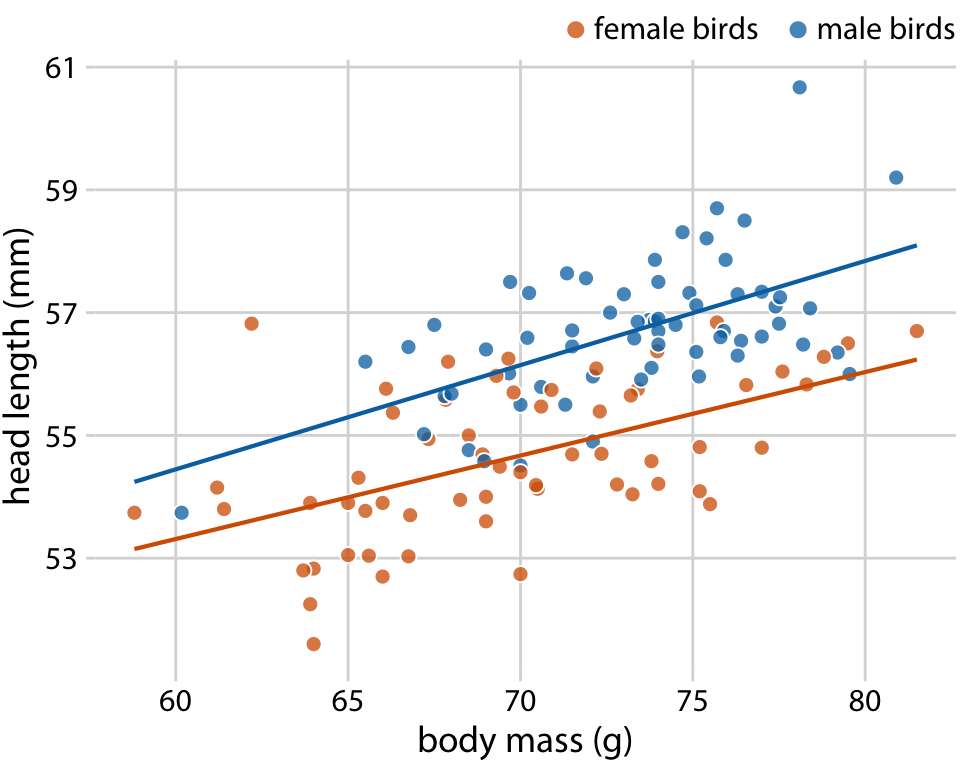
さまざまな異なる状況下で有効に働く関数は線形関数である。現実のデータセットの場合は驚くほどに2変数が線形の関係を持つことがよくある。(意訳: ので回帰直線だけで十分たたかえる。)例えば12章では鳥の頭長と体重の関係について議論した。オス、メスにそれぞれ回帰直線を引くことで読み手はトレンドを認識しやすくなる。
非線形の場合
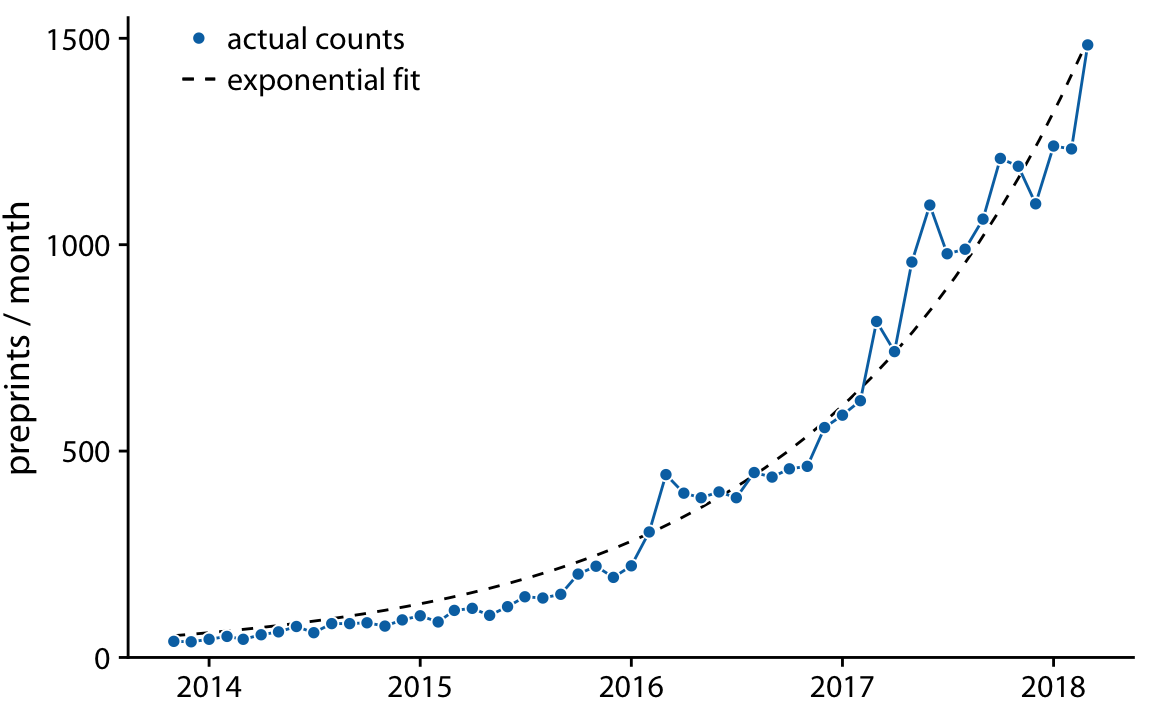
非線形の場合には適切な関数形式が何かを考える必要がある。このケースおいては変換をほどこして線形にすることで、その関数の適切性を考えることができる。ch12のbioRxivのデータを見てみよう。毎月の投稿の割合が一定に増加するという仮定をおいた場合、投稿数の曲線は指数関数になる。この仮定はbioRxivのデータにおいて14-8のグラフをみると適合しているようにみえる。
もとの曲線がという形式の場合、logをとると
と線形に変換できる。そんなわけでlog変換した後のグラフをプロットして線形性を持つか確認することは、元の関数が指数性をもつかどうか決定するうえで適切になる。実際対数軸としてグラフを書くと線形性をもつことが確認できる。
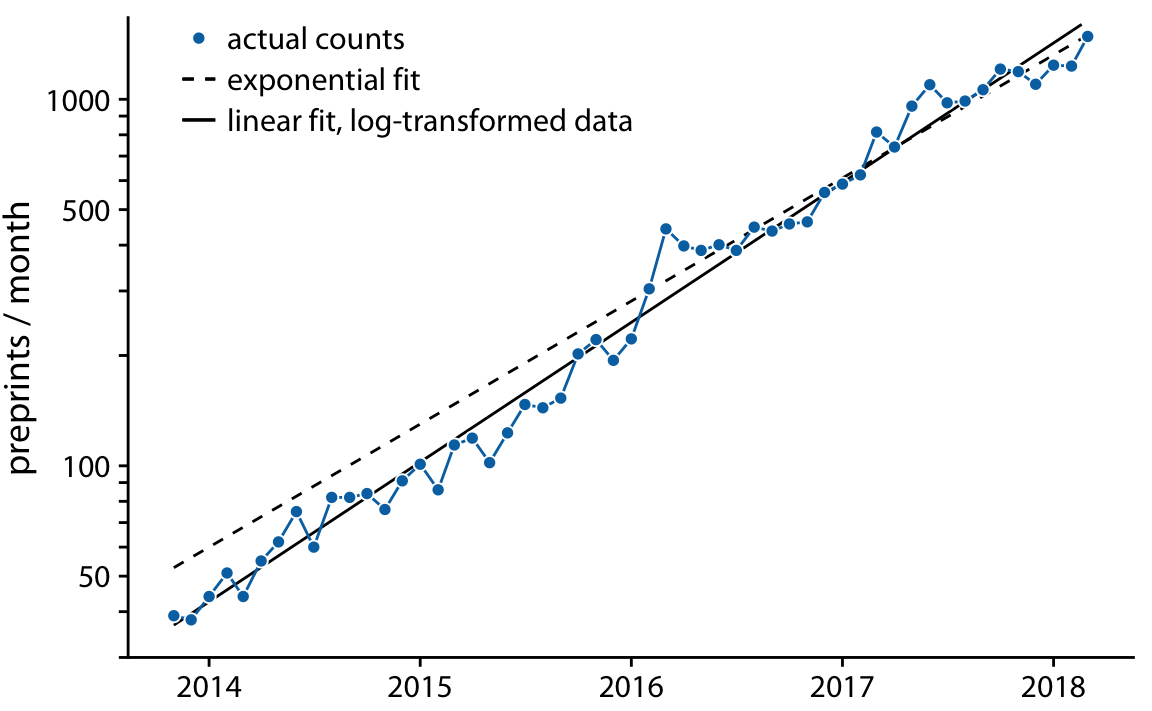
非線形関数の回帰について
上では指数関数にたいしてそのまま回帰したものと、log変換したあとに回帰したものを重ねている。2つは似ているが異なっている。これは指数関数に対して直接回帰したときによく生じる問題である。指数関数の最大値付近では誤差も相対的に巨大になるので、log変換せずに回帰すると最小値付近の誤差の影響が小さくなる。その結果最小値付近でオーバーシュートしたりアンダーシュートしてしまう。一般に非線形な直線に対してそのまま回帰しようとせずに、線形に変換した後回帰するのが望ましい (だけど全ての関数が線形にへんかんできるわけではもちろんない)
3. デトレンド
長期トレンドが支配的な時系列データにおいては、トレンドを除いて変動をハイライトするという方法が効果的である。これはデトレンドと呼ばれる。(変数がトレンド+変動であらわせるということを仮定しています)ここでは住宅価格のデータをみながら説明していく。
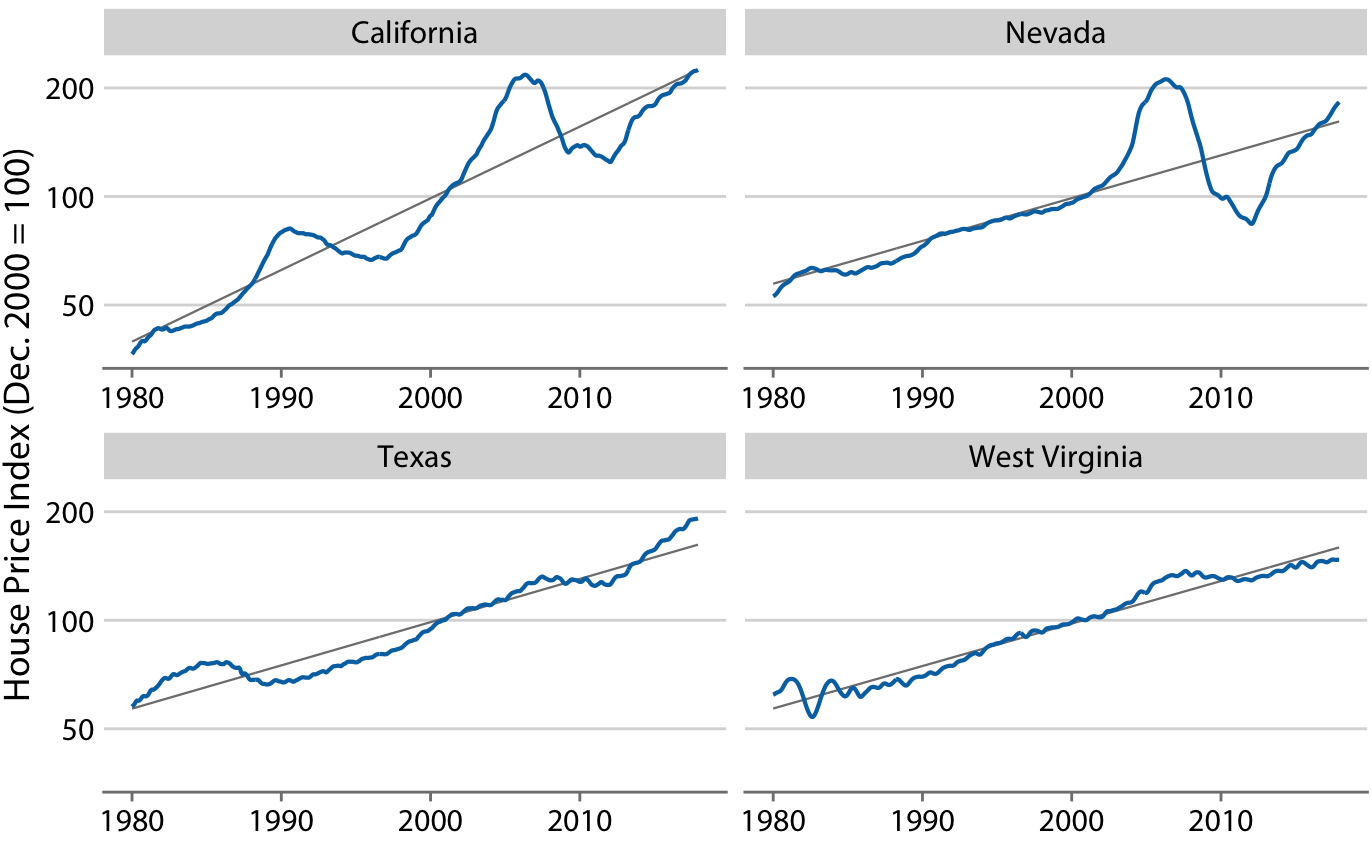
長期的には、住宅価格はインフレと同期しながら上昇していく。しかしこのトレンドの上には住宅バブルが重なっている。下図は実際の住宅価格のトレンドである。例えばカリフォルニアにおいては2回のバブルがあることが観測できる。住宅価格は指数的に上昇するのでグラフは対数スケールになっている。
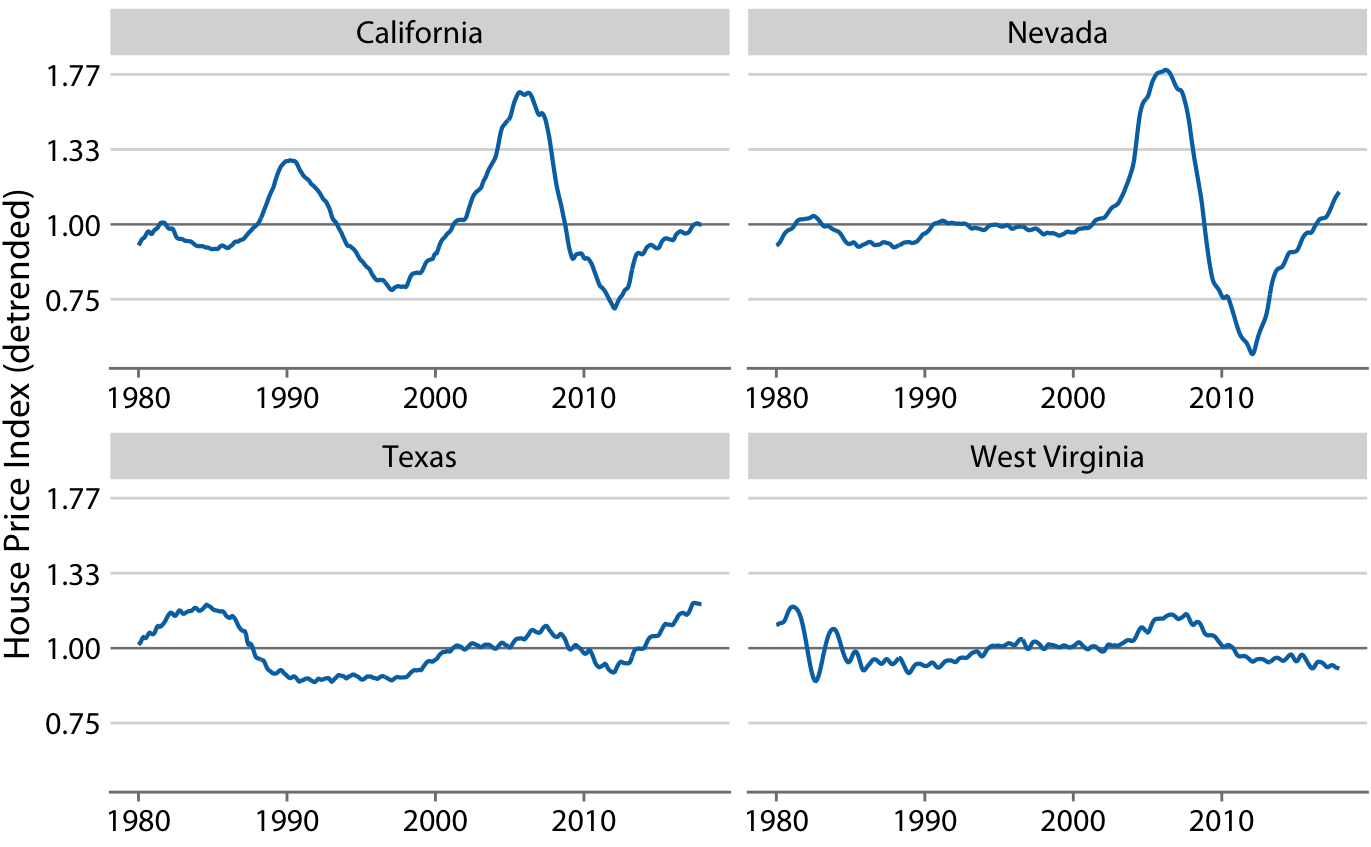
これらの実際の価格の指数を長期トレンドの値で割ることでデトレンドした住宅価格をえることができる。(対数スケールなので割り算の操作はグラフ上は引き算に見える)。デトレンドによって予期しない変動が強調されるので住宅バブルの影響がより鮮明に見える。例えばNevada州の80sなかばの暴落の影響はデトレンドした後だと顕著に見える。
季節成分の考慮
単純なデトレンドだけではなく、時系列を複数の成分に分解することができます。一般的には長期トレンドに加えて
- ランダムノイズ
- 外部要因による影響
- 周期的(季節など)な変動
の要素の存在を仮定する。(のちにCO2濃度を扱いますが、CO2濃度 = トレンド成分 + 季節変動 + 何らかの外部要因 + ノイズとしてモデリングできるということを仮定しています)そしてこれはSTL分解と呼ばれます。(また通常ランダムノイズは平均0の正規分布に従うというような仮定をおき基本的には各成分に対する変動は無視することが普通だと思います。
周期的な変動を持つ時系列のデータを考えるためKeeling曲線(CO2濃度のグラフ)を考えて分解する。
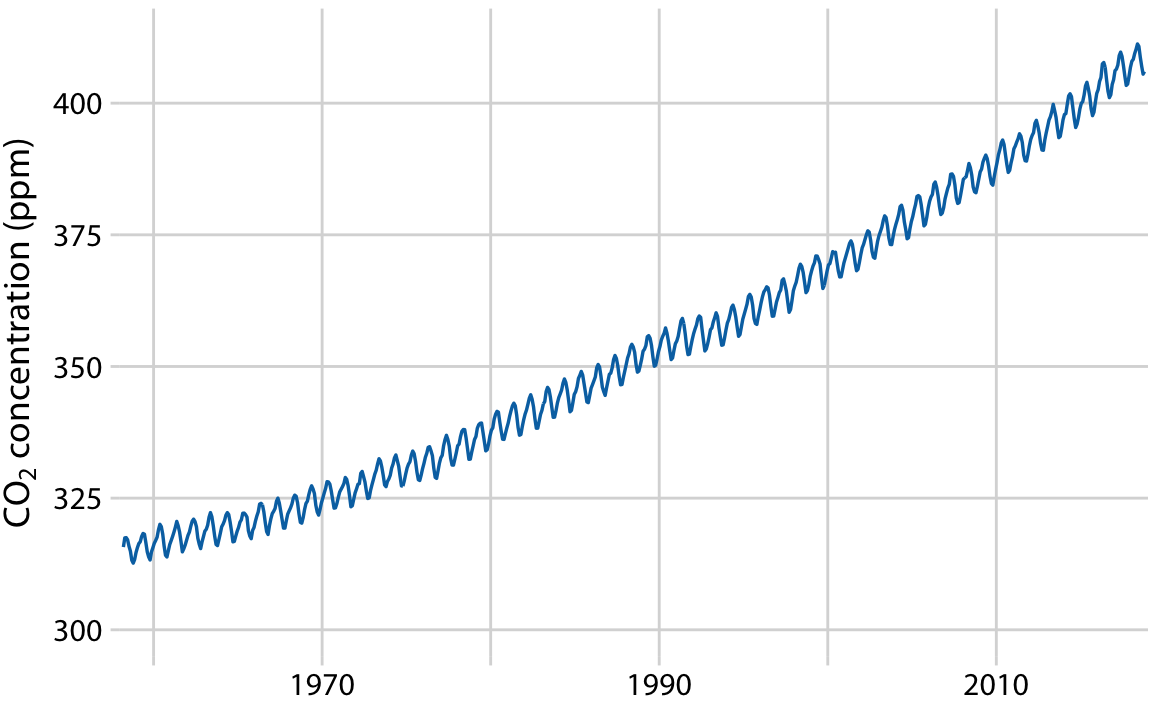
CO2濃度は線形より少しだけ早く増えているように見える。またCO2は1年周期の変動のトレンドがあるように見える。 Keeling曲線は長期トレンド、季節成分、残差に分解される。
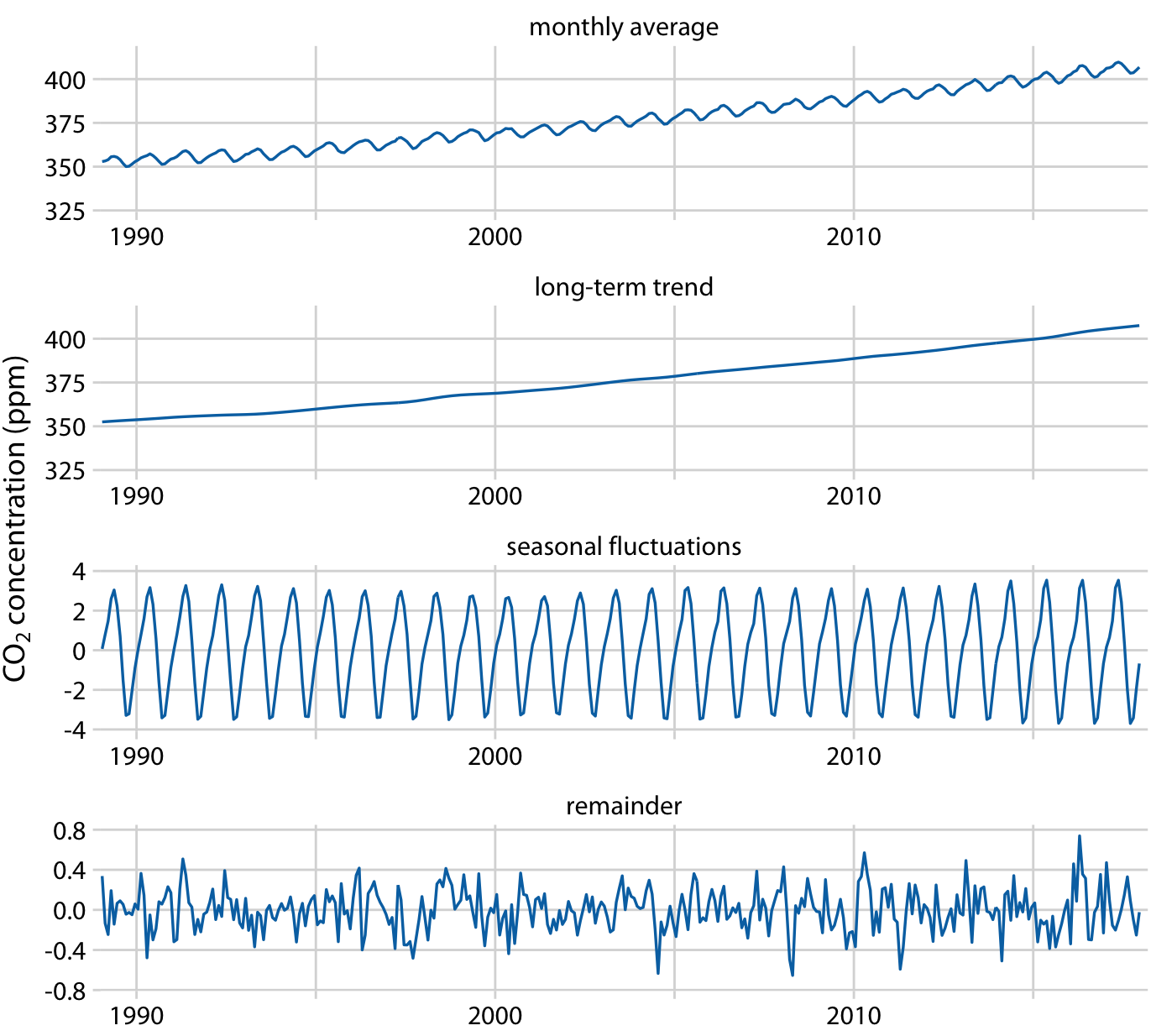
長期トレンドをみれば50ppm上昇していること、季節変動の変動が8ppmに収まることがわかる。 残差にはランダムノイズと外部要因による影響が含まれるが、残差の変動が1.6ppmにおさまっていることから火山の噴火というような外部要因が無いことがわかる。